
今まで飲んだ中で一番おいしかった酒は何ですか。
北から南まで1000を超える酒蔵があり、それぞれが大吟醸、吟醸、純米などたくさんの製品を出しています。
純米大吟醸がおいしいのは間違いないですが、純米酒を熱燗にするのがいいという人もいて、人それぞれ色々な好みがあります。
一番おいしいお酒は何ですか?と聞かれるのは一番悩む質問ですよね。
あれもおいしいし、これもおいしいし、色々飲めば飲むほど日本酒の奥深さを感じます。
この問題を解決するために、「一番おいしいお酒」を計算する方程式を発明しました。
自分では一滴も酒を飲まずに、数式を計算するだけで一番おいしい酒を決めることができます。
まさに呑兵衛の呑兵衛による呑兵衛のための数式です。
abstract
お酒のおいしさを科学的に定量するために、従来味覚センサや味覚物質の測定などの手法がとられてきた。しかし味覚は繊細なので、官能検査を完全に置き換えるほど正確で信頼性のある定量方法はまだ存在しない。そこで新しいアプローチとして日本酒のアワードの結果をメタアナリシスで統合することを試みた。アワードごとに賞の選定基準が違うため受賞の価値を統合するためには重みづけが必要である。重みを決定する方法として、アワード順位を応募数で規格化し、順位率を定義した。これにより全ての賞、全ての年、全ての部門を単一の数式で定量的に評価することができ、この順位率をもとに得点を算定し結果を統合し、おいしい酒、おいしい蔵を推定した。
はじめに
 一番おいしい日本酒はどれなのでしょうか。
一番おいしい日本酒はどれなのでしょうか。
呑兵衛なら誰しも一度は考える素朴な質問です。その答えを数式を用いて計算で求めてみたい。
シンプルな仮定にもとづいて方程式を立て、そしてその解を得る。
味見もせずにそんなことが本当にできるのか。
丁寧に回答解説を行います。
背景
おいしいとは何なのでしょうか。おいしい食べ物を開発するために世界中の料理人が日夜研究をしています。しかしおいしいとは何なのか意外なほどわかってはいないのが現状です。味覚受容器がどう作用するかなど深くわかっていることもありますし、五味のバランスや、うま味物質の発見は世界に誇る日本の偉大な研究成果でしょう。しかしそれだけですべてがわかっているという訳ではありません。例えば味覚物質はかなりの数が同定されていて、最先端の装置を使えば物質を定量的に同定することが可能です。しかし、その測定された物質を混ぜ合わせたからと言って同じ味にならないから不思議なものです。日本酒なんて主成分のほとんどは水で、次がエタノール。残りの微量物質が味を決定しています。人間の味覚はどんな測定機よりも繊細で、微量物質を感じ取れるのです。そして厄介なのは個人差が非常に広いということです。
もちろん味覚物質を一本一本測定しておいしさを求めるのも一興です。機会があればぜひやってみたい。また味覚センサというものも近年では開発が進んでいるようです。そういう方法もあるでしょう。それにチャレンジしている本職の研究者の方もたくさんいらっしゃいます。しかし最高の酒を見つけるには数万本も酒を準備してコツコツ測定するのはいささか道のりが遠いです。お金もかかりますし。
結局のところ、おいしさの研究は進んでいるものの、実際に現場でおいしさを判定するために使われているのは官能検査、要は味見なのです。もちろん訓練されたパネラー(テイスター)の方がなさっていて、審査の再現性が得られているので検査方法として充分に信頼性は担保されています。では同様に数万本の酒を一つずつ味見をして決めますか。ぜひやってみたいです。飲兵衛の夢ですね。ワインアヴォゲート誌がやっているパーカーポイントというワインの格付けポイントがあります。近年日本酒の格付けをしたのですが、1300の酒蔵から日本酒、主に大吟醸を1本ずつ集めて全部試飲してポイントを決定したそうです。1300種を飲んでもまだごく一部でしかないのです。なかなか気が遠くなりますね。
ロバート・パーカー・ワイン・アドヴォケートが認めた 世界が憧れる日本酒78 (Amazon)

では何か他の方法は、と探してみると色々なランキング、アワードがあります。これがおいしい酒ですよ、一番ですよと教えてくれます。
雑誌などメディアが発表しているランキングは独自の調査に基づくものと書かれていることが多いですね。口コミだったり、ネットの検索数、アクセス数、SNSの発言回数、はたまた販売数まで。居酒屋にアンケートを送って集計するなんてものもありました。これはこれで一面の真実なのだと思いますが、その銘柄のブランド力が強く出ていて味だけで判断した結果とは言いがたいのではないかという疑いがあります。
そうするとブラインドテストの結果が気になってきます。ブラインドテストとは銘柄などを伏せた状態で審査をする方法です。こうすれば先入観なしに判断を下すことができます。

全国新酒鑑評会をはじめとした各種アワードがブラインドテストをやっています。この結果を信じればいいのでしょうか。しかし、ここに大きな問題があります。日本酒の酒蔵は国税庁課税部酒税科酒のしおり平成31年3月によると1594蔵あるそうですが、この1年間に与えられた金賞以上の賞の数は主な賞を数えてみると1764ありました。なんと酒蔵の数より多いのです。道理でよく金賞受賞という酒を見かけるなと思いました。
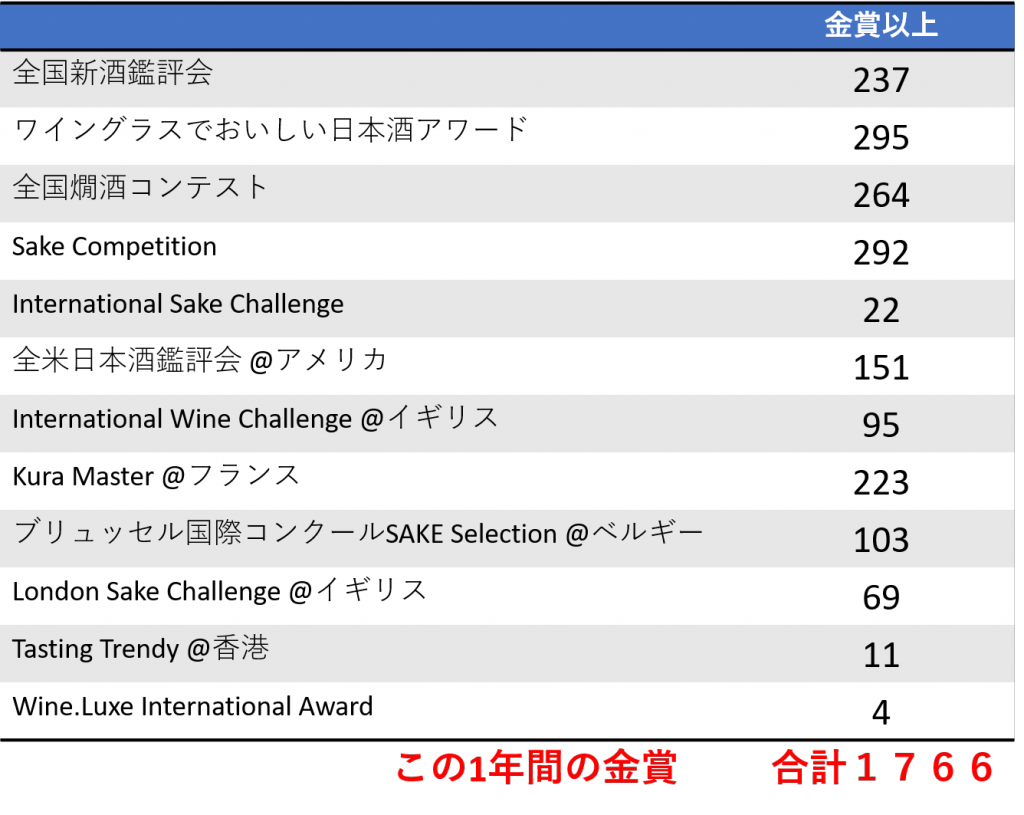
そう、これが世に言う、「金賞多すぎ問題」です。

金賞と一口に言っても、それぞれの受賞の価値が違います。
全国新酒鑑評会では上位30%に金賞を与えていて、一方でSake Competitionでは上位3%程度に金賞を与えています。1位を決める賞もあるし、上位8割に何らかの賞を与える賞もあります。それぞれの賞の考え方が反映されていて面白いですね。
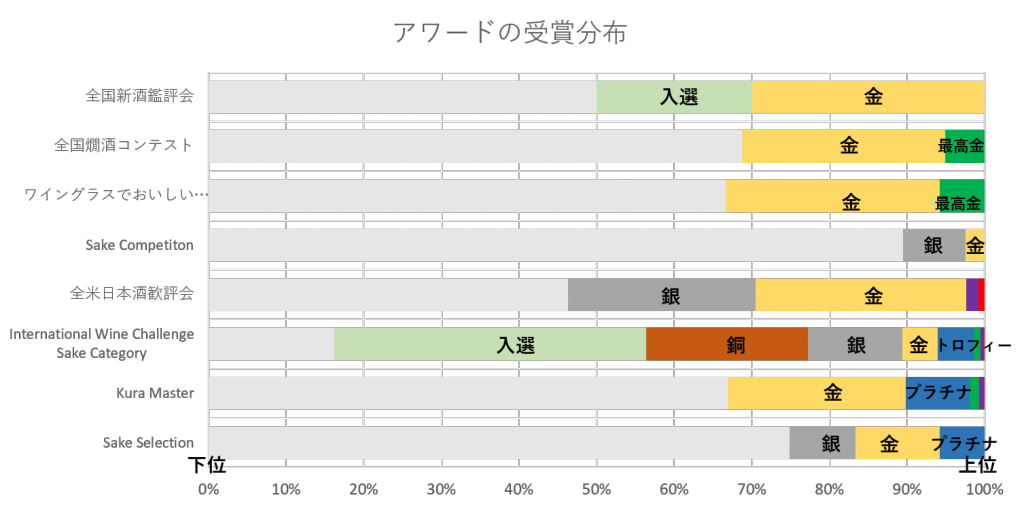
ただこれではあれもこれも大体のものはおいしいってことになりますから、誤解を恐れずに言えばあまり意味をなしていないのです。金賞多すぎという批判に対して、「だってどれもおいしいんだもんしょうがないじゃん」的な回答(大意)をした方がいらっしゃったような気がしますが、確かにと同意する部分もあります。でも知りたいのはおいしいのがどれかじゃなくて一番おいしいのがどれかということですよね。
改めて考えてみると、お酒のおいしさとアワードで審査員が下す評価点数には比例関係があります。しかし、アワードでの順位は評価点数と順位は必ずしも一致しません。アワードでも順位からおいしさを逆算して推定することはできそうな気はします。しかし、その推定にはおいしさの分布関数が必要な情報になりますが、おいしさの分布はガウス分布とは限らないなんらかの分布形をとると思われ、その分布形状ははっきりしません。味覚物質や味覚センサの測定値から算出することができれば分布形状くらいは特定できそうな気もしますが、今の技術では難しいです。またこの分布形状は評価項目や評価方法などでも変わりうるので確定させるのはやはり難しいです。
しかし、これを逆用することができるのではないかと考えました。金賞受賞をポイント化して全てのアワード結果を統合すれば少なくとも一番おいしい蔵を決定できるはずです。
一口に統合すると言っても、金賞の価値の違いはそれぞれ過ぎて単純に、金賞1つを1ポイントの価値とみなすような単純な計算式では統合することができません。これまで様々なスポーツなどで行われてきた統合ランキングはすべての結果の条件が統一されているので、このような素朴な手法でランキングの統合が行われてきました。例えばサッカーの勝ち点はわかりやすい事例です。1勝したらもらえる勝ち点3は相手が強かろうが弱かろうが同じです。今回のように様々な条件が混在する場合にはその価値に応じた重みを付けるのが常道ですが、その重みを理論的に決定するためには詳細な条件が必要です。例えば相手の強さに応じて1勝の価値が決まるイロレーティングが挙げられます。これはチェスや将棋、最近ではFIFAのサッカーランキングなどがそうです。しかし今回の日本酒アワードの結果は様々すぎる上に、選出プロセスは原則的に非公開である以上は重みを決定するための材料が残念ながら足りないようです。
八方ふさがりのようですが、統合という難題にメタアナリシスという手法で立ち向かいます。メタアナリシスは実験結果の試行回数が少ない時に別々の人がやった別々の実験結果を数学的な手法で取捨選択し、統合してより確からしい結論を導く方法です。今回はこれの基本的な考え方を用いてアワードを統合してみます。
実験方法
ここで一旦、賞がおいしさを代表し、賞からおいしさを推定するという野望から一度離れてみます。賞は何を表しているのでしょうか。考えるまでもないことですが、おいしさを点数化して順番通りに並べて上位から賞を与えていきます。そこはどのような賞も同じです。暗黙の前提条件というもので、改めて言葉にするとそんな当たり前のこと今更何をバカなことを言っているのかと思うでしょう。しかしここに問題を解くカギがありました。
改めて考えてみると、我々が知りたいのは、「一番」おいしい酒であり、おいしさの絶対値、つまりどれくらいおいしいのかではないということに思いいたります。だとすると、酒のおいしさの相対値で構わないということです。
あるアワード結果に対して順位率Rという新しい概念を定式化します。
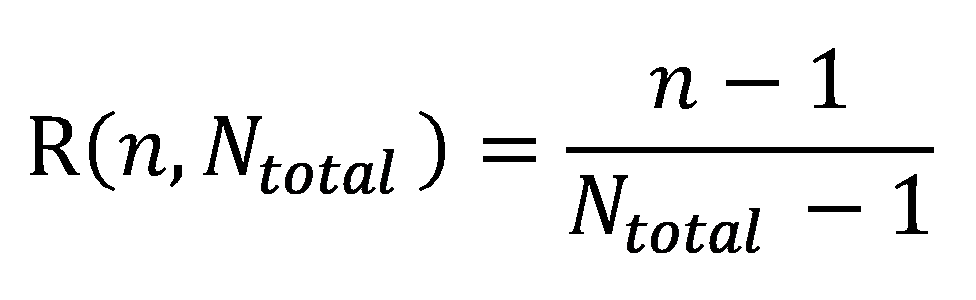
ここでnは順位、Ntotalは応募総数とします。1位の時にゼロ、最下位の時に1になる0から1までの指標です。これはつまり順位を応募総数で規格化するということです。これが1位2位という順位を決定した場合、その価値はどのくらいなのかを見積もる根拠となります。
出てきた結果を万人向けにわかりやすくするために、1から引いて100倍し、1位を100点、最下位を0点として線形に対応し点数化します。この点数化に数学的な意味はないのですが、一般向けにわかりやすさを重視してこのような式に変形し、改めて定義します。これを順位点Pと呼びます。
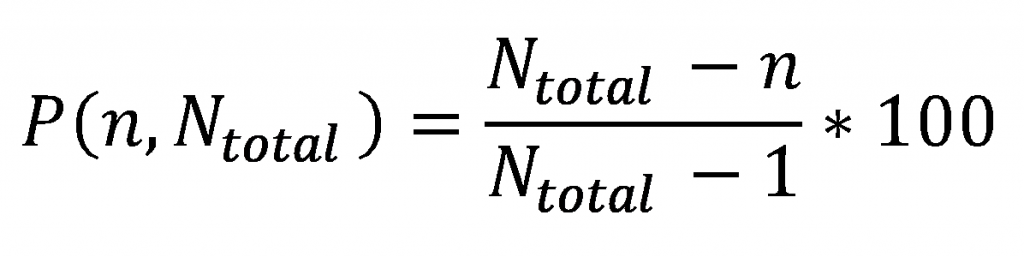
これだけでは何も産まれませんが、ここで一つ仮定を立てます。あるアワードに応募している酒蔵の集合はすべての酒蔵の集合と同等であるとします。つまりおいしい蔵ばかりが応募していたり、反対にまずい蔵だけが応募していたりといった、応募することによる偏り(応募バイアス)がないとします。実際には休眠している蔵があり、また応募してもどうせ落ちるから応募しないと思っているようなところもあると思われるので何らかの偏りはあると思いますが、ここではそういう仮定が成り立つとします。同等というのはあまり数学的な言葉ではないですが、おいしさを定量化した時に分布の平均値や分散が一致するというくらいの意味合いで考えておいてください。この仮定が成り立つためには、アワードの応募数が十分に多いことが必要です。この閾値を決定するのは難しいですが、例えば蔵の数が1500程度なので1割で150程度は必要なのではないかと思われます。また応募する際に特別な条件がないということも必要でしょう。例えば日本国外で製造された日本酒が応募できる海外日本酒部門があるアワードなどが挙げられます。そのような事例は除外する必要があるでしょう。
この仮定を入れるだけで順位率は俄然と意味を帯びてきます。アワードの中での順位は全体の蔵での順位率と等しいということになります。
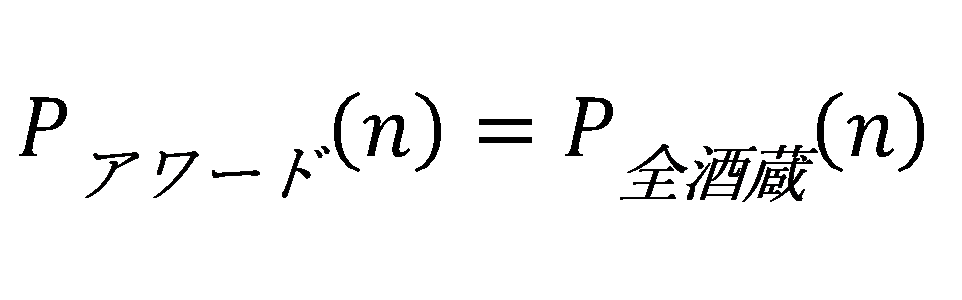
95点なら、全体で上位5%のおいしさという意味を持ちます。
個別の賞の順位を規格化することで、全ての賞の全ての年度の全ての部門の結果をこの一本の数式で書き下すことができます。同じ賞でも年度ごとによって難度が違うこともありますが、それもこの数式でやすやすと計算することができます。また年によって賞のレギュレーションや受賞数が変動しても特別な処理をすることなく同一の式で対応できます。統合する際の重みの算出を規格化で代用したという言い方もできるかもしれません。数学的な言い方をすると、過去に行われてきた集計方法では得点pを求めるのにP=P(n)として順位のみの関数として算出されてきました。そこに任意の重み係数wが変数として入ることもありました。今回はP=P(n,Ntotal)として変数が増えているところが最も違う画期的なところです。
具体的な順位ではなくて、上位何%に金賞というように詳細がわからない賞もあります。内部の得点や順位が非公開な以上は勝手に推定することはできません。そこでこの場合にはそのカテゴリの最上位点と最下位点の平均を得たとします。最上位に合わせる、最下位に合わせる、どちらの考え方もあると思いますが、中央値とするとアワードがそのカテゴリに割り振る点数が順位ごとに割り振った点数と同じになるというメリットがあります。今回はこれを採用します。数式で書くと以下のようになります。
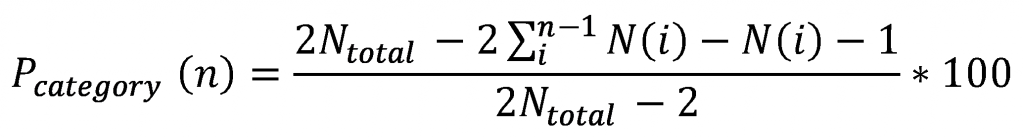
ここでN(n)はn番目のカテゴリとして賞を授与された総数とします。
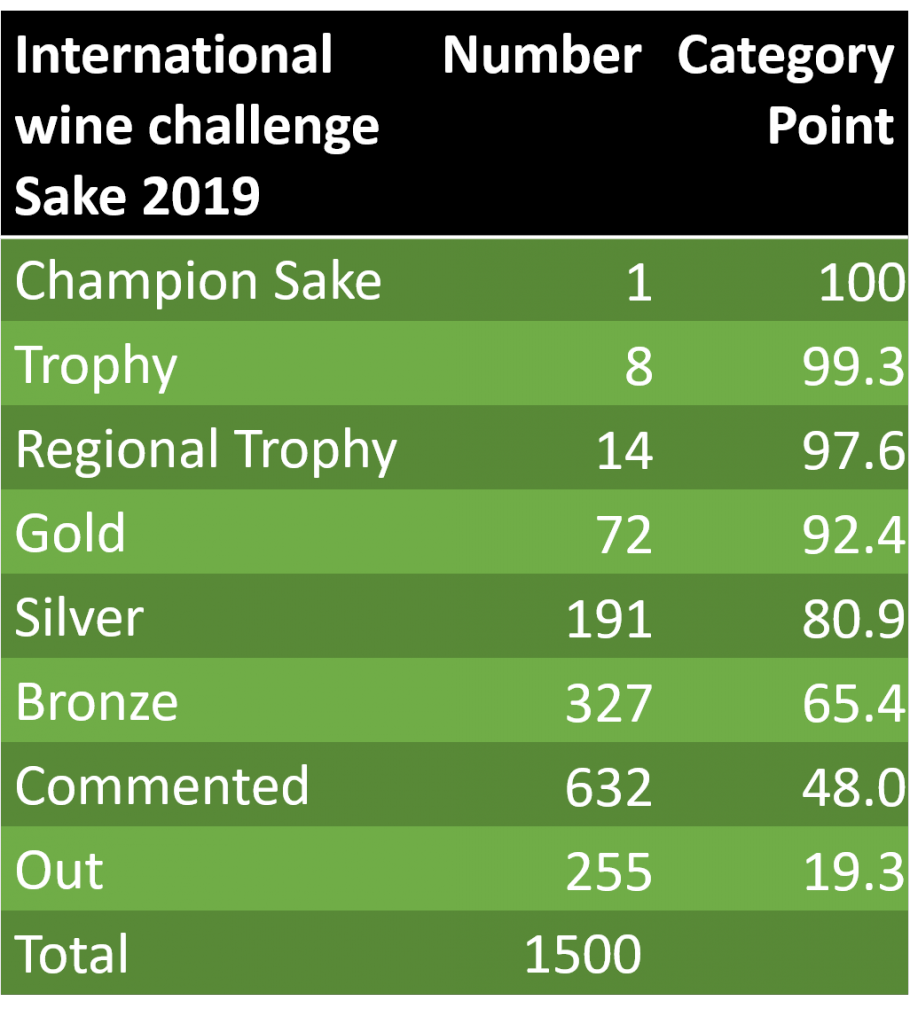
一例としてInternational Wine Challenge Sake Category 2019の計算結果を示しておきます。
さて、ここまでくれば仕事はほとんど終わったも同然です。全てのアワードの全ての受賞結果に対して順位点を計算し、それを統合すれば自動的に順位が決まります。注意しておかないといけないのは出てくるポイントは蔵の相対的な順位を反映した指標であり、おいしさを直接反映した指標ではないということです。1位と2位はほぼ同じくらいの味で少し差がついて3位があるとしても、順位率、順位点では等間隔で差がついています。あくまでも順番を表した指標であるということを忘れてはいけません。1位は2位の2倍おいしいという意味でも、100点は50点の2倍おいしいという意味でもありません。慧眼の方は個別の酒と酒蔵の話がごっちゃになってしまっていると疑問を持っているでしょう。ここまであえて酒と酒蔵を区別せず混用してきました。実際のところ、日本酒は同じ銘柄で同じスペックだったとしても毎年同じ味になるとは限りません。同じ味になるように杜氏さんは苦労なさっている訳です。大体同じ味であるとしても、完全に同一の化学成分の分布をしていて完全に同一の味ではないという意味合いです。また同じものでも毎年、材料や作り方を変えている蔵もあります。毎年違う名前で酒を販売している蔵もあったりします。消費者に届くまでの保存状態などを考慮に入れると無限に味の幅が広がります。そうすると最高の一本を選ぶのはほとんど不可能です。そこでおいしい酒を造っている酒蔵を割り出せば、その蔵が作っている酒が一番おいしいはずという仮定で間接的においしい酒をあぶりだすのが今回の趣旨になります。以後は一番おいしい酒ではなく、一番おいしい酒蔵を割り出すという前提で話を進めていきます。順位点は酒でも蔵でもどちらでも通じる概念です。もし十分な試行回数が得られるなら酒で算出してもいいでしょう。
ただいくつか条件を整える必要があります。まずは数多あるアワードからデータ解析に耐えうるものを選別します。選別条件は以下としました。
- 応募数が充分に多い
- どんな蔵も応募できる
- 一般人ではない専門のテイスター
- ブラインドテスト
- 味以外の評価項目がない
- 全応募数が公開されている
- 審査結果が一覧として公開されている
1,2については既に説明したように、一様分布仮定が必要なためです。3は審査員があまり一般人過ぎると評価がブレる可能性があります。4は必須であり、ラベルが見えるとブランドによる先入観がはいってしまいます。5も同様です。あくまでも味のみで評価しているアワードに限定します。6は計算をするために必須で、意外と公開していないアワードもあり、大きなアワードでも計算の除外となったものもあります。7は必ずしも必須とは言えないのですが、計算結果の透明性を担保するために必要だと考えました。
これらの条件を満たすアワードとして以下の8つを選出しました。
- 全国新酒鑑評会(独立行政法人酒類総合研究所 審査員 酒類総合研究所、国税庁の酒類鑑定官、都道府県醸造試験場の技術関係者 日本で最も古いアワードで参加蔵数最大(850蔵)のアワード 主に大吟醸しか出品されない 1部門 1911年開始 日本)
- Sake Competition(SAKE COMPETITION実行委員会 審査員 技術指導者、有識者、蔵元 内閣府や省庁などの後援を得ている。7部門 2012年開始 日本)
- ワイングラスでおいしい日本酒アワード(ワイングラスでおいしい日本酒アワード実行委員会 審査員 日本酒業界の幅広い業種の関係者 ワイングラスで試飲するスタイル。4部門 2011年開始 日本)
- 全国燗酒コンテスト(全国燗酒コンテスト実行委員会 審査員 日本酒業界の幅広い業種の関係者唯一の燗酒コンテスト。45℃55℃の二つの温度で試飲。4部門 2009年 日本)
- 全米日本酒歓評会(U.S. National Sake Appraisal. 審査員 日本人8名、外国人3名の専門家 最も歴史の古い海外の日本酒アワード4部門 2001年 アメリカ)
- International Wine Challenge Sake Category(William Reed Business Media Ltd 審査員世界の日本酒・ワイン業界関係者 世界最大規模・最高権威に評価されるワイン・コンペティションの日本酒部門 9部門 2007年開始 イギリス)
- Kura Master(Association de Kura Master 審査員 フランス中心のヨーロッパの飲食関係者 外国人のみで審査をする珍しい賞 4部門 2017年開始 フランス)
- ブリュッセル国際コンクールSake Selection(ブリュッセル国際コンクール 審査員 40か国350名の業界関係者 ベルギー政府経財省後援。日本酒カテゴリはできたばかりだが、ワインをはじめ様々な分野での歴史がある。 7部門 2018年開始 ベルギー)
ブラインドテストは実験的には当然二重盲検法をとるべきですが、ブラインドテストが行われているとしても、1重か2重かについて厳密に記載しているアワードはないようです。数百数千の酒を審査するのでサーブする人がどれがどれなのか把握しているとは思えないので、おそらく結果的に2重盲検法になっているのではないかと推察しています。
統合時には複数出品の取り扱いが最難関です。多くのアワードで複数出品を認めています。部門1本目は無料だが2本目から出品料がかかるというアワードもあります。また全国新酒鑑評会のように複数出品は不可だが醸造場所が違えば別の蔵とみなすなんていうわかるようなわからないような基準をとっているところもあります。これは小さな複数の酒蔵が共同で出資した1つの法人名を使っている事例や、大手が小さな蔵を買収して看板だけかけ変わっている事例など歴史的な経緯で厳密に立て分けることは難しかったからなのですが、結局広い土地を持ち、いくつも製造工場を持っている大手の蔵が複数出品することを止められなくなっていて線引きの難しさを感じます。複数出品があると大きく二つの問題が生じます。一つ目は全ての出品酒に点数がついてしまうと最高点、最低点、平均点などの手法で蔵の点数を決める必要があります。出品するためにはお金が必要なのでたくさん出品できる資金力がある大手の蔵が有利ということになります。平均や最低点とすると、一品しか出品していない蔵では最高の酒を出しているはずなのでそれはアンフェアで真の実力を反映していない気もします。複数出品していても同じ蔵で同じように作ればそんなにブレはないのではないかと推察されます。アワードではオーソドックスなもののほうが評価されやすいので、変わり種の酒を試しに出品してしまうと低い点数がついてしまいます。しかし、その点数はその蔵の実力を反映したものとはやはり言えないでしょう。今回は様々なケースを検討した結果、出品酒は酒蔵で一番おいしいものであり、それが蔵の実力を体現するという立場をとり、複数出品酒の中の最高点のみを採用することとしました。
それに伴い副次的に生じてくる問題は総出品数の確かさです。複数出品のうち最高点だけを採用すると、それ以外のものはノイズとなります。上位の蔵はどれを出しても高い点を取ってくるので、中下位の酒蔵は不当に点数が下がってしまいます。除外した分だけ総出品数から差し引けばよいのですが、アワードは基本的に選外となった下位の酒は非公開なので正確な出品数を割り出すことはできません。今回の計算は上位ランキングを確定するのが主目的であることを考えると、選外の情報がないことによる数値の誤差は下位に行くにしたがって高まるのでここは目をつぶり、公開情報だけから総出品数を暫定値として代入することとしました。数学的な議論は煩雑になるので割愛します。
算出された結果をどう統合するかも重要です。
まずは足切り基準です。各アワードをその蔵が全体でどのくらいの位置にあるかを調べる実験とみなして統合するのですが、そうすると1回のアワードが1つの実験結果に相当し、信頼性を高めるためには可能な限りたくさんの試行回数が必要となります。回数は多ければ多いほどいいのですが、色々な賞に真面目に全部応募している蔵はほぼありません。酒蔵の自由意思で応募しているだけなので、こういう賞レースに興味のない蔵は一切応募していません。1回だけ応募してまぐれ当たりで高得点を取ってしまう可能性もあり、それが真の実力を反映しているとは必ずしも言えないでしょう。また今回は公開情報のみで集計をしているために、一度まぐれで高得点を取り、それ以外は選外となった場合では出てきた点数の平均をとると高得点のみが反映されてしまい、正しい評価点を知ることができません。それを考慮すると、ある程度の回数の受賞回数で線引きしてデータの信頼性を担保する必要があると言えます。
また受賞しているアワードの種類も複数あったほうがよいと考えられます。アワードごとに審査基準が違うため、一つの測定値を複数の実験手法で相互に確かめることに相当します。データの信頼性を上げるためには複数のアワードから評価されていることも重要だと考えられます。
また複数年度のデータについても同様です。試行回数を増やすためには複数年のデータを統合したほうがよさそうです。しかし、期間が長すぎると蔵の作る酒も変化しますし、杜氏さんをはじめとした作り手が変わることもあるでしょう。あるいは賞の審査基準や審査員が変わることもあり得ます。長い期間をとりたいですが、そういった審査の不確定性を減らすためには長すぎてはいけません。
これらの条件は適切な足切り期間を割り出すのは難しいので、今回は独断で過去5年間、3種類以上のアワードで、10回以上の受賞をしていることを足切り基準としました。
もう一つ考えておきたいのは、総得点を合計で出す積み上げ方式か、平均で出す方式かということです。スポーツ界のランキングなどでは積み上げ方式がよくとられているようです。これはほとんどのプロスポーツではほとんどの試合に参加しているなどトップランクのプレイヤー、チームはほぼ同じ条件で戦っていることが暗黙の前提条件となっています。日本酒のアワードでは積極的なところは8種類のアワードに全部出していますが、それはごくごく一握りです。現時点では上述の金賞多すぎ問題の影響でたくさん受賞してもあまり販売に貢献しないという問題があり、いくつかの賞でよい結果が得られればいいという認識になっているのではないかと想像しています。ですから、もし積み上げ式でトップを決めようとすると多くの賞に出している蔵が圧倒的に有利になり、受賞した点数が何点かよりも、いくつのアワードに出品したかでトップが決まってしまいます。今後、ほぼすべてのアワードに出品することが標準的にならない限りは積み上げ式は採用できないため、現時点では時期尚早であると言えます。
ここまでで、基本的な統合の方針を定めることができました。基準の決定に曖昧さがあり、多くの恣意性は否めませんが、ひとまずはこれで結果を出してみます。
結果
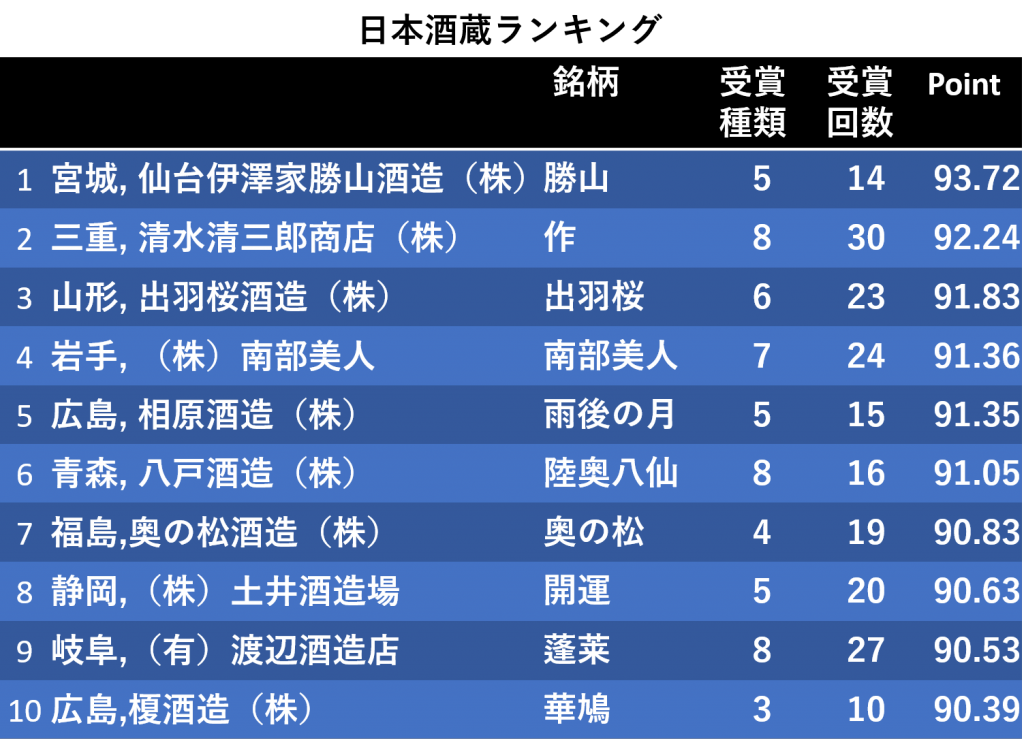
統合結果は以下のようになりました。
10位 広島,榎酒造(株),華鳩
華鳩 貴醸酒10年熟成大古酒 600ml (Amazon)

9位 岐阜,(有)渡辺酒造場,蓬莱
蓬莱 聖地の酒巫女ラベル [ 日本酒 720ML ] (Amazon)

8位 静岡,(株)土井酒造場,開運
開運 特別純米 720ml (Amazon)

7位 福島,奥の松酒造(株),奥の松
奥の松酒造 純米大吟醸プレミアムスパークリング 720ml (Amazon)

6位 青森,八戸酒造,陸奥八仙
陸奥八仙 大吟醸 720ml (Amazon)

5位 広島,相原酒造(株),雨後の月
雨後の月 大吟醸酒 月光 720ml (Amazon)

4位 岩手,(株)南部美人,南部美人

3位 山形,出羽桜酒造(株),出羽桜
出羽桜 雪漫々 大吟醸 5年氷点下熟成酒 720ml (Amazon)

2位 三重,清水清三郎商店(株),作
作 雅乃智 中取り 純米大吟醸 720ml (Amazon)

1位 宮城,仙台伊澤家勝山酒造(株),勝山

栄えある一位に輝いたのは宮城の仙台伊澤家勝山酒造(株)でした。こちらは2019年のIWCでChampion SakeとKura MasterでPresident賞というナンバーワンの賞をダブル受賞しています。ブラインドテストで高得点を確実に取れるのはやはり圧倒的な実力があるからなのだと思います。


上位陣はかなりの賞に積極的に出品していることもうかがえます。おそらくどこかで飲んだことがあるという有名な蔵が多いとは思います。しかし、おいしいと有名な蔵が漏れていたりするのでやはりブラインドテストで真の実力が洗い出されたと言えるのかもしれません。しかしかなり狭い範囲に点数が分布していて、少しの違いで順位がかなり入れ替わりそうです。
議論
結果が妥当なのかどうかを検討していきましょう。
順位点の点数はすべての蔵の中での順位を反映している指標であると定義しました。しかし最高点は90点台前半で90点を超える蔵は数えるほど。定義によれば、90点以上の蔵は1500蔵の1割を指すので、150蔵程度はあるはずです。しかしそうなってはいません。大きく二つの理由が考えられます。一つは各アワード結果のばらつきがあるため平均をとると低かった時の点数が足を引っ張り点数が下がる効果です。点数の最高位は当然1位なのでどんなにぶっちぎりで審査の点数がよくても頭打ちしますが、悪い時はどこまでも下がってしまいます。このような場合には総合点にはバイアスがかかり、結果として悪いほうに落ち着きます。もう一つはカテゴリ点の定式にあります。カテゴリの最上位と最下位の点数の平均を与えているので、上位陣は点数が押し下げられ、下位陣は点数が押し上げられています。これは現在公表されているデータだけからはどうしようもない問題です。内部の評価点数がわかればいいのですが、それがわかるならこのような間接的な手法をとる必要がそもそもなくなってしまいます。最も影響が大きそうなのは全国新酒鑑評会です。上位30%に金賞を与えるのが最高の賞になっており、ということは金賞を受賞しても85点にしかならないということになります。90点を超えるような点数の蔵は全国新酒鑑評会に出品しないほうがよいということになってしまいます。ただ全国新酒鑑評会の点数よりも上位の蔵はそう多くはなく、実際には大して影響はないかと思われます。全国新酒鑑評会は100年を超える歴史があり、かなりの数の蔵が毎年出品されている最も権威のある賞だと思います。長年洗練された手法で審査が行われ、日本酒の技術力向上に多大な貢献をあげてきた賞です。それがこのようなネガティブな事例の対象となってしまい悲しい気持ちでいっぱいです。しかしこれはどうしたものなのか。こちらでは解決策がないので、とりあえずこのままでいこうと思います。
逆の意見もあるかもしれません。賞ごとにばらつきがあり、ブレがあるとすると、90点以上の蔵があるのはむしろ高すぎるかもしれません。ここの定量化はすごく難しいので、妥当なのかどうかについてはまだ評価できていません。
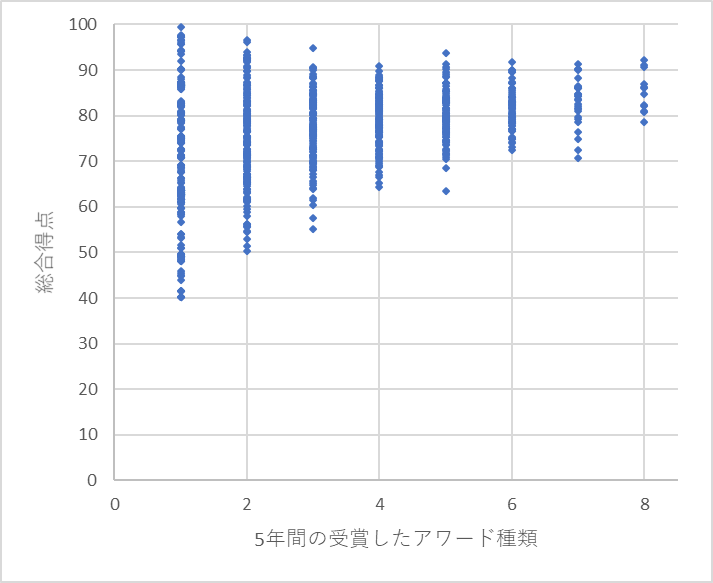
ここで受賞種類と受賞回数と総合得点の関係を見てみましょう。図のように少ない回数でばらけているのが、回数が増えるに従ってばらつきが減り、平均値が少しずつ上昇しているのが見て取れます。良い点を取れる蔵が何度も応募するという傾向がはっきりと見て取れます。上述のように足切りを設けましたが、このグラフを見るとその妥当性が見えてきます。1回2回だけ高得点をとっている蔵がありますが、回数が少なく信頼性が担保されたとは言えないので除外したほうがよさそうです。それぞれの回数の最高点をプロットすると一度下がってまた上昇していくのがわかります。その最低値と足切り基準が大体一致しています。これが足切りの妥当性を保証していると言えます。
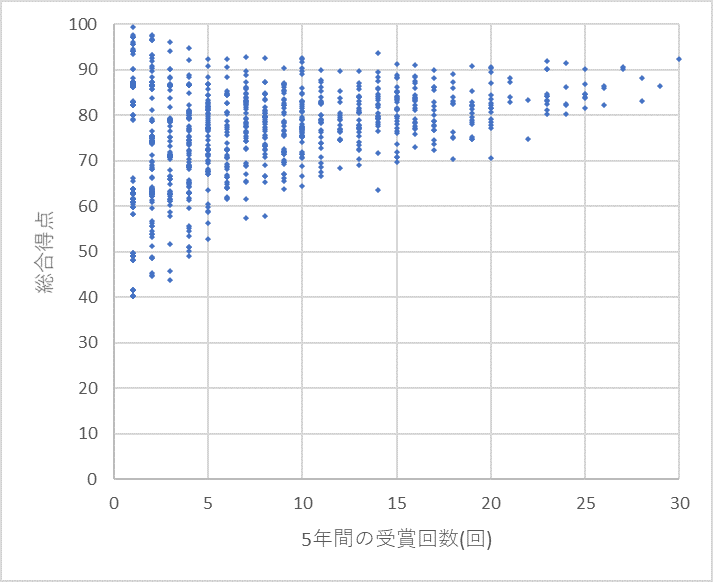
また最低点が40点程度であり、0点ではないのですが、これは選外を計算に入れていないためです。もし選外もすべて公開していればもっと最低点が下がります。上述のように、積み上げ式ではなく、平均で総合点を出していて選外が計算にはいっていないことから、ここに公表バイアスの効果があることが見えます。下位の点数は信頼性が非常に低いと言わざるを得ません。
結論
順位率、順位点を定式化し、その結果を統合し一番おいしい酒蔵を算出することに成功しました。順位点は複数の賞を定量的に見積もっているので、賞の結果を単純に四則演算することができます。統合するだけに留まらず、様々な効果を順位点により定量的に解析することが可能となるでしょう。
そして酔っぱらっててもちゃんと計算はできるってことを証明することにも成功しました。80分後に忘れてそうで怖いです。
今はこの結果がほんとうなのかどうか、トップ10の酒を並べて飲み比べたい。
謝辞
いつもおいしい日本酒を作ってくださる全国の酒蔵と、各種アワードで毎回膨大な数の日本酒を審査してくださっている方々やそれを支えてくださっている方々に深い感謝をいたします。
大阪大学 生命機能研究科 小林竜馬

コメント